Overview
Load testing validates that your voice AI agent performs reliably under concurrent call volume — not just in isolated test calls. Running multiple evaluators simultaneously reveals infrastructure bottlenecks, latency spikes, and quality degradation that single-call testing won’t surface. Cekura’s load testing works through the frequency parameter. When you set frequency toN, each evaluator runs N times during a single evaluation cycle. With 10 evaluators at frequency 5, that’s 50 concurrent calls hitting your agent.
Prerequisites
Before starting load testing, ensure you have:- An active agent configured on the Cekura dashboard
- At least 1+ evaluator(s) that passes when run in a vaccuum
- A baseline run completed for your evaluator(s), so you have a benchmark to compare your load testing results against
- Your concurrency settings* properly configured on both Cekura (settings -> organization -> general -> parallel call/chat limit), as well as on your provider’s side.
* The Developer plan has a limit of 10 concurrent calls. For higher allowances or any questions, feel free to contact us at support@cekura.ai.
Default Metrics
Cekura provides three metrics that are automatically applied to every load test run — Talk Ratio, Infrastructure Issues, and Latency. You can optionally enable Expected Outcome as well for an added layer of verification that your core flows are still working under load. All other metrics can be disabled for load testing runs.Step-by-Step Process
1
Run a Baseline at Frequency 1
Run your evaluator(s) once with frequency set to 1. Record:
- Expected outcome pass rate
- Average latency per evaluator
- Infrastructure issue count (should be 0)
- Talk ratio norms
2
Set the Frequency
In the Cekura dashboard: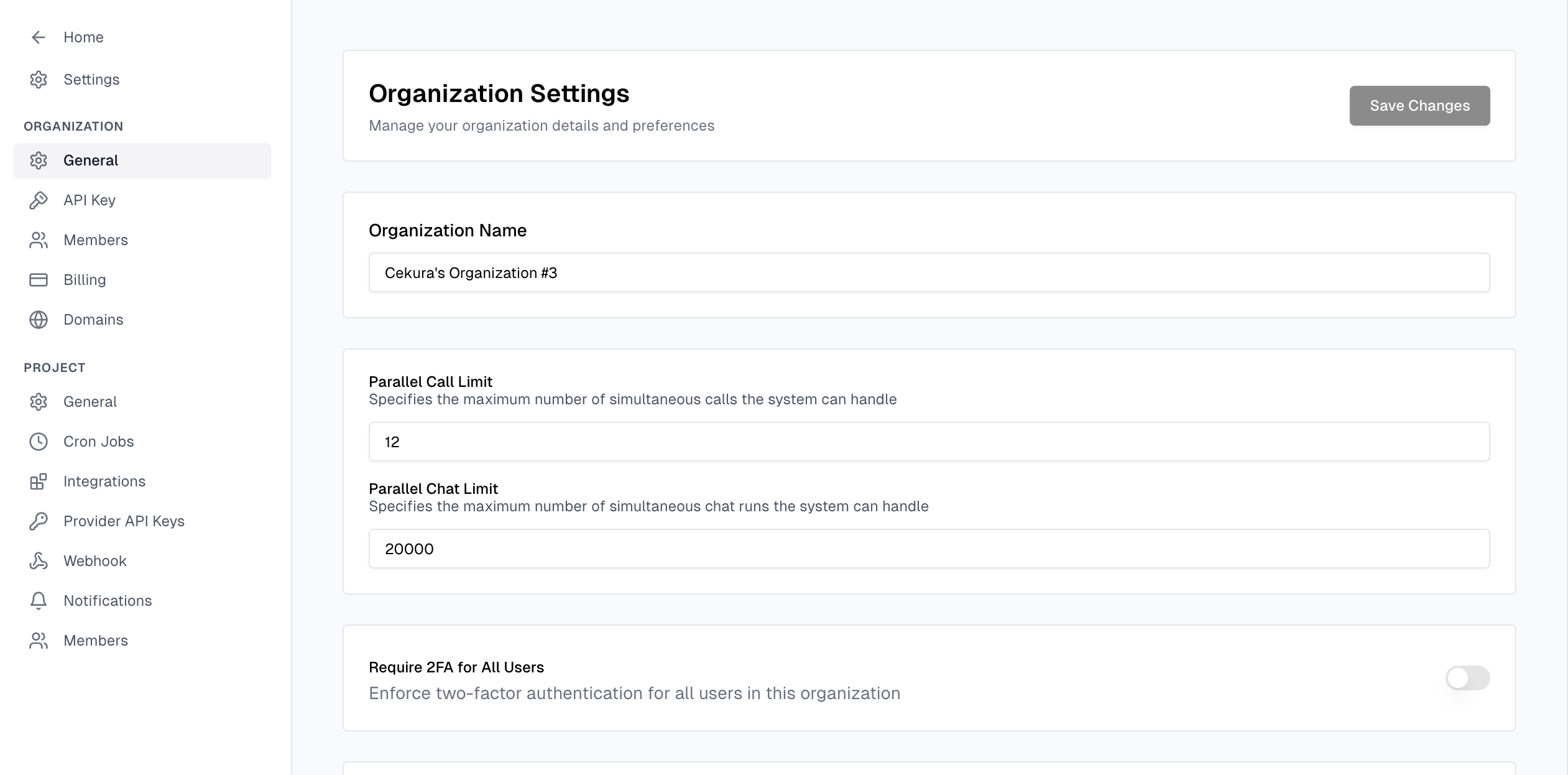
- Navigate to your agent’s Evaluators tab
- Select the evaluators you want to include in the load test
- Set the Frequency field to your target number
- Click Run
3
Scale Gradually
Don’t jump straight to high numbers. Increase incrementally so you can identify exactly where degradation begins:After each step, compare results against your baseline before increasing further.
Cekura schedules calls at a rate of 5 CPS (calls per second). At higher frequencies, ensure each call is long enough so that all scheduled calls are running concurrently.
For example, 50 calls requires a minimum call length of 50 ÷ 5 = 10 seconds, and 100 calls requires 100 ÷ 5 = 20 seconds.
If calls are too short, earlier calls may finish before later ones start, meaning you won’t hit true peak concurrency.
4
Interpret Results
After each run completes, compare the three default metrics against your baseline:
- Latency — A consistent 1–2 second increase is a yellow flag. Spikes above 5 seconds mean your infrastructure is under strain.
- Infrastructure Issues — Any non-zero count at low frequency is a bug, not a load problem. At higher frequencies, these indicate you’ve hit a concurrency ceiling.
- Talk Ratio — Significant shifts from baseline suggest the agent is behaving differently under load (longer pauses, repeated phrases, or truncated responses).
- Expected Outcome Pass Rate — If evaluators that pass at frequency 1 start failing at higher frequencies, conversation quality is degrading under load.
Concurrency Limits
If your current plan’s concurrent call limit is lower than what your load test requires, reach out to support@cekura.ai to discuss upgrading your concurrency allowance.
Best Practices
Start with Passing Evaluators
Load testing should surface infrastructure problems, not prompt issues. If an evaluator fails at frequency 1, fix it before including it in a load test.Isolate Variables
Don’t change your agent’s prompt and run a load test at the same time. You won’t know whether failures are from the prompt change or the increased load.Test at Realistic Peaks
If your agent typically handles 20 concurrent calls in production, test at 20, 30, and 50 — not just 100. You want to know your headroom above real-world usage, not just the absolute ceiling.Run Each Level Multiple Times
A single run can be noisy. Run the same frequency 2–3 times and look for consistent patterns rather than one-off spikes.Monitor Downstream Systems
Cekura tests the agent, but if your internal and/or external systems that the agent depends on (i.e. toolcalls, for example) can’t handle the load, you’ll see failures that look like agent problems. Check your backend logs alongside Cekura results.Related Resources
- Suggested Testing Approach — Build a solid evaluator suite before load testing
- Evaluators Overview — Design effective test scenarios
- Mock Tools — Use mock tools during load tests to isolate agent performance from backend dependencies