Overview
Monitor your Pipecat-based voice agents with Cekura’s observability tools. Automatically capture transcripts, audio recordings, tool calls, and session metadata with minimal integration effort. What you get:- Complete agent side conversation transcript
- Tool/function calls with inputs and outputs
- Dual-channel audio recording (agent + user)
- Session metadata for correlation and debugging
Prerequisites
- A Cekura account with an API key
- A Pipecat agent project
Setup
Integrate the SDK in your Pipecat agent
Add the Cekura tracer to your Pipecat agent with three simple steps:What this does:
- Initialize the tracer with your API key and agent ID
- Observe your pipeline to capture transcripts and tool calls
- Register task handlers to enable audio recording
- Captures transcripts, tool calls, and session metadata
- Records dual-channel audio for analysis
- Exports data to Cekura observability endpoint
Configure Pipecat provider in Cekura
Navigate to your agent settings in the Cekura dashboard and select Pipecat as the provider:Required configuration:
- Provider: Select “Pipecat” as your voice integration provider
- Agent ID: Your unique agent identifier from the Cekura dashboard
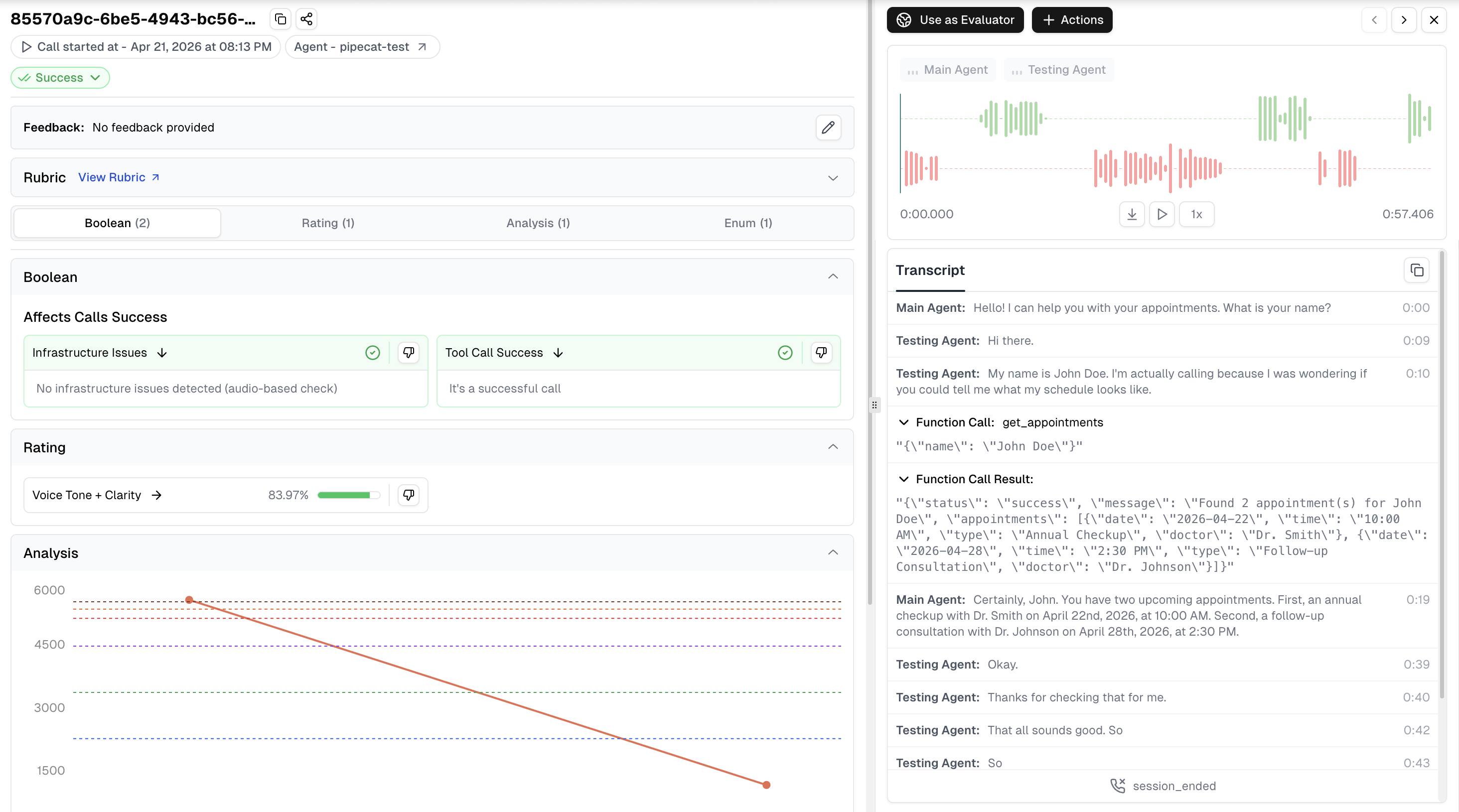
Enhanced Data in Cekura UI
With observability enabled, you’ll see enriched information in the Cekura platform:- Complete Transcript: Full conversation history with UTC timestamps
- Tool Calls: Function call requests and responses with inputs and outputs
- Session Metadata: Session IDs for correlating Cekura calls with your logs
- Audio Recording: Dual-channel recordings (agent + user) for quality monitoring
SDK Reference
PipecatTracer Initialization
observe_pipeline()
Adds observability to your Pipecat pipeline. Captures transcripts, tool calls, and session metadata.register_task_handlers()
Registers cleanup handlers for automatic resource management when the session ends.CEKURA_OBSERVABILITY_ENABLED="false": Disable observability entirely
Troubleshooting
Missing Aggregators Warning
If you see:LLMUserAggregator and LLMAssistantAggregator for transcript capture. Add aggregators to your pipeline:
Import Error
If you see:Best Practices
- Use environment variables for credentials: Don’t hardcode API keys in your code
-
Keep the SDK updated: Run
pip install --upgrade cekuraperiodically for the latest features - Use session IDs: Pass custom session IDs to correlate Cekura data with your application logs
Next Steps
- Create custom metrics to evaluate your agents
- Set up automated testing for your Pipecat agents
- Explore predefined metrics